
1. dev
llmbox を公開
新しいアプリ msrks/llmbox を Open Source で公開した。 localLLM システムの DevOps Platform でコンセプトは以下の通り。
- Prompt Training: OPROを参考にして Data-Driven で Prompt を最適化する。
- 100% Local Stack: App, DB, Storage, LLM が全てローカル。
- Cloud Deploy も容易: DB は Postgres、Storage は S3 Compatible にしているので、Cloud Deploy も環境変数を変更するだけで簡単。
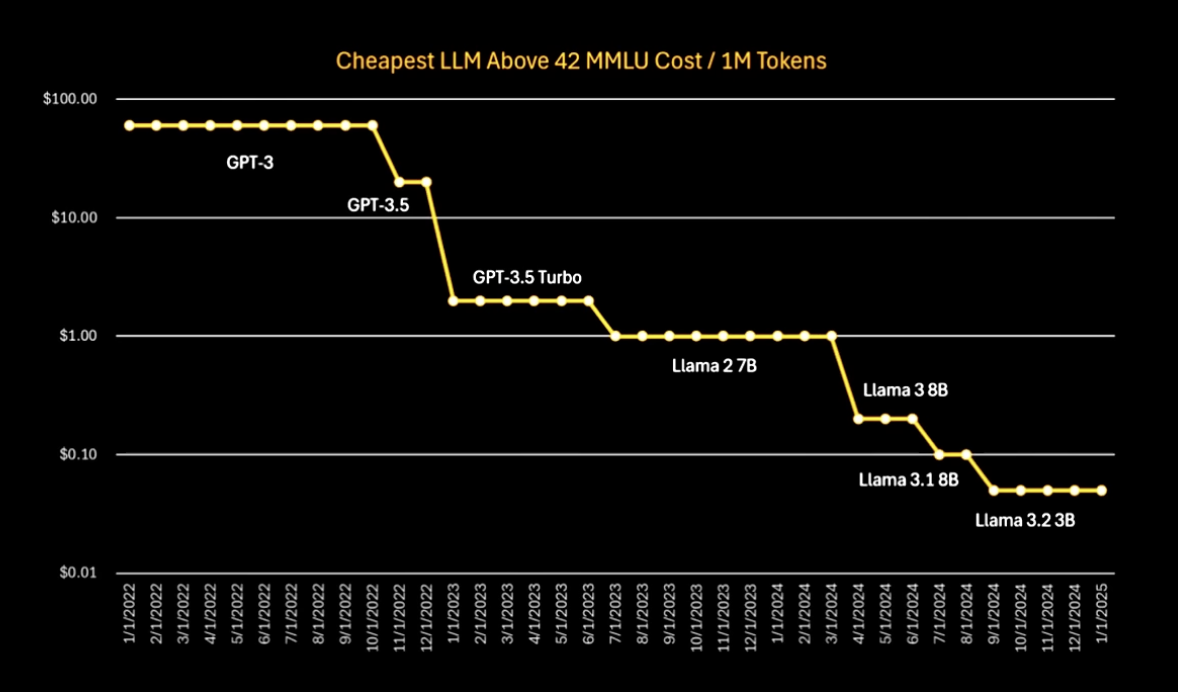
とりあえず技術実装してアプリにしたが、性能評価はこれから。 いずれにせよ、今後も AI の性能とコストは劇的に下がり続けるので、近視眼にならずに AGI Ready なシステム設計を意識したい。 (コストは 1 年で 1/10。性能改善によるインパクトは超指数関数的)
The socioeconomic value of linearly increasing intelligence is super-exponential in nature. (Sam Altman Blog)
localLLM 推論速度評価
2022 年 M2 Macbook Air 16GB の環境で llama3.2-vision:11b を評価した。 demonstration example は無しの zero-shot 推論とした。 プロンプト評価時間は 1.7 秒、生成時間は 8.9 秒で計 10.9 秒だった。 プロンプト評価時間が思ったより短かったのはポジティブなサプライズ。
M2 チップ(GPU 性能 3TFLOPS、メモリ帯域幅 100GB/s)から、M4 Pro チップ(GPU 性能 8.5TFLOPS、メモリ帯域幅 273GB/s)に変更したら、 プロンプト評価時間、生成時間ともに約 1/3 になる計算だ。例えば reasoning させないで、ok/ng だけ返させるようにしたら 生成時間はほぼゼロなので、合計でも 1 秒以内に結果が返ってくる計算になる。
とはいえ、性能が欲しいなら few-shot で demonstration example も与えたいし、reasoning させると出力 token も増えるので、 現実的には数秒オーダーになりそうだ。ちなみに 16GB だと GPU に乗り切らなかったので llama3.2 11b 動かすなら 24GB は欲しい。
❯ ollama ps
NAME ID SIZE PROCESSOR UNTIL
llama3.2-vision:11b 085a1fdae525 12 GB 7%/93% CPU/GPU 28 seconds from now
❯ python3 docs/test-vision-api.py
✅ API request successful
Response content:
{
"model": "llama3.2-vision:11b",
"created_at": "2025-02-16T21:16:34.913478Z",
"message": {
"role": "assistant",
"content": "This image depicts the main entrance to Stanford University. The building on the left is called \"The Main Quad,\" and the archway leads to Memorial Church, as well as other buildings on campus.\n\nThe photograph was taken at sunrise or sunset, as indicated by the pink sky. This picture is most likely from 2023 because of the palm trees that have been planted in recent years."
},
"done_reason": "stop",
"done": true,
"total_duration": 10879046875,
"load_duration": 44962375,
"prompt_eval_count": 18,
"prompt_eval_duration": 1715000000,
"eval_count": 78,
"eval_duration": 8896000000
}2. research
Test-time computing
アプリへの Test-time computing の実装も今後の Todo だが、ただでさえ推論スペックの制約が大きくて実行時間がかかりがちな localLLM との相性がイマイチじゃないかと思って、後回しにしている。
当初の test-time computing の研究界隈は、LLM はそのまま弄らずに post-processing の工夫だけで性能が上げられる提案があった。しかし、 ここ直近では LLM に RL で専用の Deep Reasoning モデルとして学習させているものを使うのが前提になってしまった。 そうすると ollama で使える multimodal の deep reasoning model は今のところまだないので、コミュニティーからの新たなリリースを待ちたい。 (R1 は multimodal でない)
ちなみにStanford の S1が面白い。"End-of-Response" Token を "Wait" に強制的に置き換えて、推論を継続させるというやり方で、 OpenAI の Test-time scaling Law を極めてシンプル明快な方法で再現できているのが素晴らしい。
RLHF の問題点と RL ブーム
上述したように、Test-time computing ブームは、RL(強化学習)ブームに言い換えられ始めている。 OpenAI が発明した RLHF は、RL に必要な Reward Model を人間によるランク付けデータによって低コストで実現する画期的な方法だった。しかし、次のブレイクスルーには RL が必須というのが大勢の見立てだ。
なぜなら人間の Preference から学んだ Reward Model は、Exploration を過小評価してしまうからだ。 AlphaGo が李世石に繰り出した"神の一手"は、この Reward Model では真っ先に捨てられてたどり着けない。 人間の趣向に囚われていては、自然現象(実験データ)を説明する方法として、物質が波でできていることや、時間の進み方が相対的であることを前提に考えるような、常識はずれの発想は難しい。
Scientific Discovery や Medical Research でブレイクスルーを起こす AGI 開発にマストの技術として RL が盛り上がっている。

MoE (Mixture of Expert)
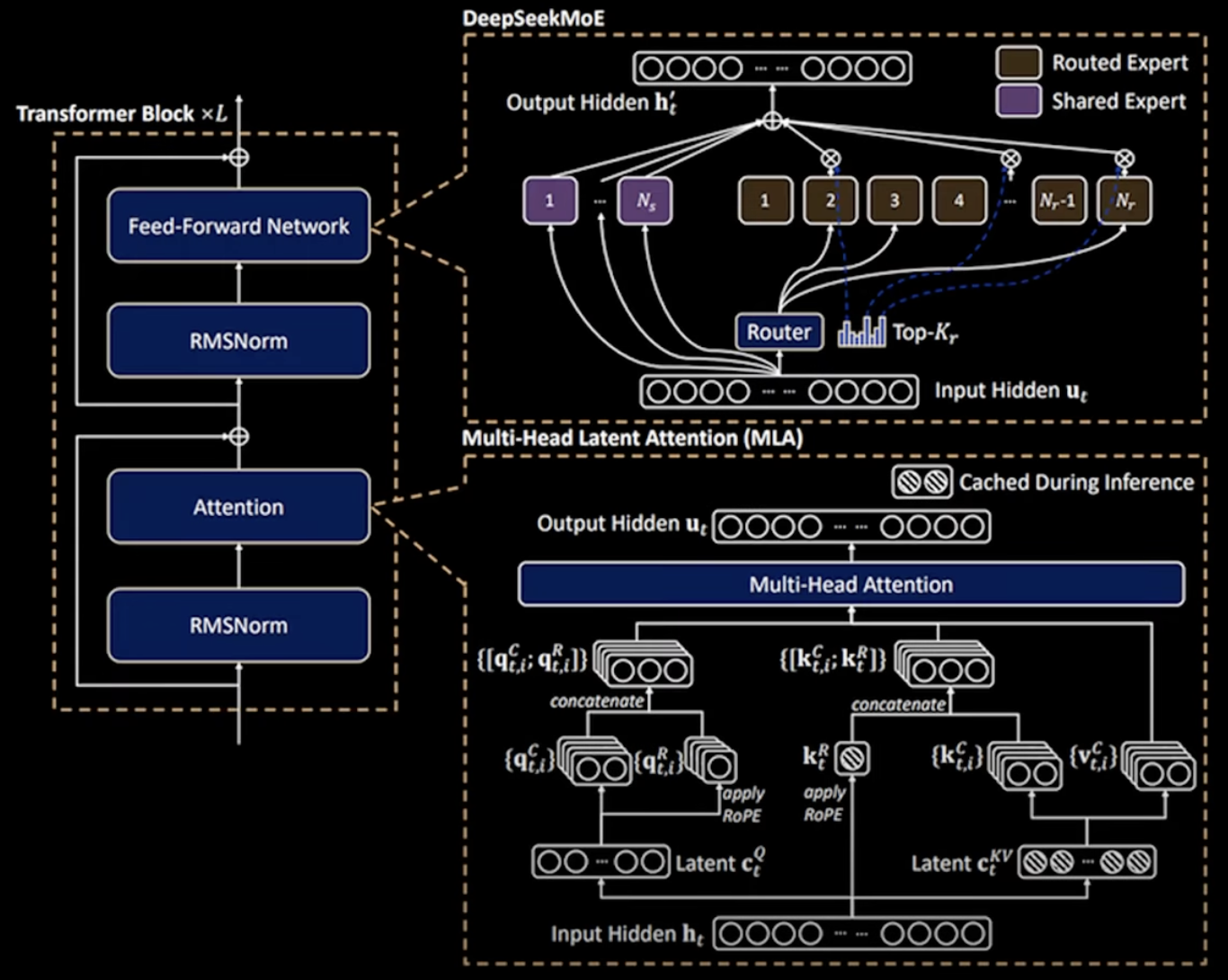
もう一つ、今後のトレンドになりそうなのが MoE だ。Deepseek のモデルでも重要な役割を果たしていて、 Deepseek モデルでは 1 度に 8 つの Expert しか有効にならない設計で、非常に計算量を抑えられている。
脳科学的にも、ヒトは前頭や側頭など役割に応じて一部だけ活性化しているということで、MoE は妥当なアーキテクチャだと考えられている。 Cohere など MoE を採用している AI Provider でもせいぜい 1/4 ぐらいの MoE だったのが、Deepseek は 1/10 以下とのことだ。 皮肉なことに米国の歪な輸出規制が生み出したイノベーションとか言われたりもしている(TFLOPS の規制は厳しいけど、メモリに関してはゆるい)。
生き残る AI のエッセンス
AI の本質的な技術は、Back Propagation による Neural Network の確率的な学習則だけという話がある。 今は昔、2012 年の AlexNet から始まった DeepLearning ブームでは、 いかにニューラルネットのアーキテクチャを工夫するかが研究の中心だった。 大量の〇〇 Net が生まれたがそれらは全て Transformer に淘汰された。
CNN や RNN も AGI のメインストリームには存在しない。 (CNN は画像全体に渡った特徴を拾うのに難があるし、RNN は長期のコンテキストを扱うのに難があった。 しかし、データ量も Computing 量も少なかった当時はうまく正則化として効いて SoTA だった)
今ではどのモデルも Transformer を採用して「Attention is All You Need」の時代だが、 Transformer も生き残らないと思っている人もそこそこいる。 Context length に対してスケールしないからだ。
すでに音声やバイオなどの long context が必要とされるモデルでは、 State-Space-Model 系のアーキテクチャが盛り上がっている(Mamba や Jamba)。 一方、MoE は生き残るかもしれないと思われている。なぜならスケールするからだ。 MoE のアイデアを使えば Expert をどんどん増やしながらも計算量はそれほど増えない。
Auto-Regressive なモデルでは、リアルタイムな動画認識・生成は難しいと思われている。 技術イノベーションで何が淘汰されるか誰にもわからないが、 スケーリングに対して相性の良い技術でないと生き残らないのは間違いなさそうだ。
4bit 量子化と 1.58bit 量子化
現在 local LLM の実行環境としては、ollama がデファクトで、4bit 量子化モデルが標準として提供されている。 元のモデルが fp32(=32bit=4byte)の場合、1/8 の量子化になる。LLama3.3 70B なんかも fp32 だと 70*4byte=280GB だが、 4bit 量子化すると 70B*0.5 = 35GB になって local PC に載せられるメモリのオーダーになる。
4bit だと 2**4=16 の状態しか持てないのに、精度を維持できるのが不思議に感じるくらいだ。 最近は 1.58bit 量子化というのが盛り上がっている。1.58 というと一見キリの悪い気持ち悪い数字だが log2(3)=1.58bit ということで、3 値量子化ということだ。 1bit 量子化の(0,1)に対して、1.58bit 量子化は(-1,0,1)の 3 値で zero を持てるのが嬉しいポイントらしい。
これでも結構に精度を維持できるのが驚きで、シリコンバレーでは 1.58bit 量子化向けの ASIC 技術が注目を集めている。 これらのトレンドを意識して、AGI-ready、localLLM-ready なシステム設計を進めたい。
@Stanford-Lab
指導教授である Carlos 先生が SAIL の Director に就任した。 引き続き環境を最大活用して知識を吸収していきたい。
この間の Lab での Lunch Talk が楽しく興味深かった。 OpenAI の Moat は何かという話。Moat は、経営工学の用語で、競合他社が容易に踏襲できない壁のことで、企業価値の源泉となるものである。
しっくりきたのは、OpenAI の Moat は "ChatGPT"が名詞化しているということだという意見。 皆が Google を使うのは Search Engine の性能が高いから使っているのではなく、「ググる」が名詞化しているからだ。Bing Search と比較どころかそもそも誰も触ったことすらない。 一般消費者的には Chatbot Arena での Score なんてどうでも良いという話。
一方で、Google の強みは Chrome を抑えているということも大きい。 そういう意味では、今 Apple は OpenAI に協力してもらっている関係だが、 OpenAI が Apple に標準ソフトの立場をお願いする関係に逆転するのは必然だという話。 とはいえ、広告モデルにできるのかは疑問だし、ToBusiness 向けだけでは Google が検索広告で稼いでいるような売り上げは立たないし、どう利益を出すかはまだわからない。 いずれにせよ結局ユーザーとの接点を握っている Apple が強いという話で終わった。
Tue: Thesis Reading Group @Lab
bi-Thu: Lunch Meeting @Lab
2/11 AI Meetup @SAP
2/12-13 AI Dev World 2025 @SantaClara
2/24 AI Meetup @GithubHQMCP、社内 RAG ツール、AI Driven Factory
JTC(Japanese Traditional Company)の話。ChatGPT の 3 世代劣化版みたいな社内 AI チャットボットを外注して開発するのは論外として、 RAG ツールもとりあえず予算が取れたから丸投げで外注しました、とならないことを期待したい。
いわゆる PDF-RAG 作るだけなら、GitHub で clone してくれば十分だ。 非構造化データだけなら Vector DB に入れて Similarity Search して、In-context LLM という教科書どおりにやれば良いだけだ。 しかし実際は RDB からデータを取得したければ text-to-sql が(sql-injection 対策も)必要だし、 API Server(Salesforce やら SAP やら)なら tool-use が必要になる。
そもそも、どこに routing するかの agentic な planning layer が必要だ。 ということで、Agentic RAG になるのが今の所の相場な感じだ。
でもここ最近で MCP(Model Context Protocol)が非常に盛り上がっていて、ロングタームで考えたら、そっちにベットしたほうが個人的には良いと思っている。 今は頑張って実装した Agentic RAG の方が MCP よりも強いという感じだが、コミュニティが強い MCP が魅力的だし、メンテナンスコストが圧倒的に低くなる。
いずれにせよ内製化する方向でいってほしい。というか自分がやりたい。 そもそも RAG なんかがゴールじゃなくて、AI Agent、AI Driven Factory となっていくと思うので、 その先も見据えた ACI(Agent Computer Interface)としての MCP の実装は開発テーマとして面白いと思う。


3. Life
旧正月を祝う会に呼んでもらい、同時に 35 歳の誕生日も祝ってもらった。Time Flies。 ワークアウトが習慣化してきているので、継続したい。
アパートにあるジムも 1 日坊主で、1 人だとやる気にならないのだが、 約 1 年、一緒にワークアウトしてきた中国出身の Alan に加えて ペルー出身の Eric とも始めたので、文化交流を楽しみながら継続したい。
